ENVIRONMENTAL DNA SEQUENCING FOR DRUG DISCOVERY
Abstract
Environmental DNA (eDNA) refers to DNA extracted directly from environmental samples (soil, water, sediments), not from cultured organisms. This includes DNA from all lifeforms present (microbes, plants, animals) regardless of whether cells are intact or extracellular. By accessing genetic material from the “microbial dark matter” (the more than 99% of microbes that are uncultivable), eDNA sequencing reveals novel biosynthetic gene clusters (BGCs) for drug leads. This paradigm opens vast untapped reservoirs of secondary metabolite potential for antibiotics, anticancer agents, and other bioactive compounds.
Modern eDNA-based drug discovery integrates shotgun metagenomic sequencing (Illumina short reads, PacBio/ONT long reads) with bioinformatic mining (antiSMASH, BiG-SCAPE) and AI-driven tools (e.g. DeepBGC, PRISM) to identify BGCs. It also employs functional metagenomics: constructing eDNA clone libraries in lab hosts (such as E. coli or Streptomyces) and screening for bioactivity. Synthetic biology further enables gene cluster refactoring and heterologous expression of cryptic eDNA-encoded pathways. Together, these methods allow de novo assembly and testing of natural product pathways without needing to culture source microbes.
A classic example is teixobactin, discovered by in situ cultivation of uncultured soil bacteria (Eleftheria terrae) using an “iChip”, yielding a potent new Gram-positive antibiotic. Similarly, metagenomic PCR screening of 2,000 soil eDNA samples for NRPS motifs uncovered the malacidin class of calcium-dependent antibiotics; targeted eDNA library cloning and heterologous expression of the malacidin BGC confirmed its structure. Marine bioprospecting has revealed rich chemistry as well: genome mining of Salinispora species yielded salinosporamide A (marizomib), a proteasome inhibitor with anticancer activity, and sponge microbiome metagenomics has identified thousands of unique BGCs across dozens of novel species. Even human and extreme-environment microbiomes harbour diverse RiPPs and enzymes with therapeutic potential.
Despite these successes, major challenges remain. Technologically, eDNA is often fragmented, leading to incomplete BGCs and assembly gaps. Sequencing errors and annotation uncertainty can mislead predictions. Heterologous expression frequently fails due to codon biases, regulatory mismatches or toxic products. Ecologically, microbial communities vary over time and space, so sampling may miss rare producers; DNA degradation and sampling bias can skew results. Legally and ethically, issues like the Nagoya Protocol on Access and Benefit-Sharing and debates over digital sequence information (DSI) complicate use of genetic data from biodiverse regions. Moreover, big data challenges (storage, annotation bottlenecks) and reproducibility demand standardized repositories and protocols.
Overall, eDNA sequencing represents a next-generation platform for drug discovery, shifting the paradigm from culturing to sequence-driven bioprospecting. To realize its promise, eDNA research must integrate advanced sequencing technologies, AI/bioinformatics, ethical global sampling frameworks, and synthetic biology for expression. This convergence will enable smarter, scalable, and sustainable mining of Earth’s genomic diversity for new medicines.
1. Introduction
1.1 Context and Importance
The discovery of new antibiotics and bioactive natural products has stagnated. As Ling et al. (2015) note, “Most antibiotics were produced by screening soil microorganisms, but this limited resource of cultivable bacteria was overmined by the 1960s”. Meanwhile, antimicrobial resistance (AMR) is rising globally. The WHO and others warn that resistance is outpacing the introduction of new drugs, creating a major health crisis. Traditional cultivation-based pipelines like the “Waksman platform” repeatedly rediscover known compounds, yielding few novel scaffolds (Nowak, 2023). With about 99% of environmental microbes uncultivable by standard methods, the vast majority of nature’s biosynthetic potential remained unexplored (Ling et al., 2015). In this context, environmental DNA (eDNA) sequencing has emerged as a disruptive strategy: instead of culturing organisms, one extracts and mines their DNA directly from the environment. This bypasses cultivation bottlenecks, enabling access to “microbial dark matter” and the myriad cryptic biosynthetic gene clusters (BGCs) it harbours (Ling et al., 2015; Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020). By leveraging metagenomics and synthetic biology, eDNA-based discovery promises a renaissance in natural product drug leads.
1.2 Scope and Objectives
This review critically evaluates the role of eDNA in drug discovery. The research begins by defining eDNA and discussing how metagenomic approaches unlock secondary metabolite biosynthetic pathways inaccessible by culture (AL Aboud, 2024). It then surveys current methodologies: high-throughput sequencing (short- and long-read), assembly of metagenome-assembled genomes (MAGs), functional expression libraries, and synthetic refactoring. It highlights case studies where eDNA mining yielded novel bioactive compounds like teixobactin, malacidins, and salinosporamide A. It also examines failures and translational gaps (e.g. expression challenges, ecological reproducibility). It discusses the major challenges – technological ones such as fragmented DNA, data overload; ecological ones such as sampling biases, and ethical or legal challenges such as the Nagoya Protocol, and digital sequence information. It explores how AI and bioinformatics like machine learning BGC predictors, in silico screening, and cloud platforms are enhancing this field. Finally, this research offers strategic, multidisciplinary recommendations such as global repositories, standardisation, synthetic biology investment, and ethical frameworks for advancing eDNA-driven drug discovery.
Top UK Assignment Cities
2. Fundamentals of eDNA and its Role in Drug Discovery
2.1 What is eDNA?
Environmental DNA (eDNA) is broadly defined as DNA isolated from environmental samples such as soil, water, sediments, biofilms etc., in contrast to genomic DNA extracted from known specimens (Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020). Importantly, eDNA is a catch-all term: it encompasses genetic material from all organisms present – microbial, meiofaunal, macrofaunal – within the sample (Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020). It includes DNA contained within intact cells (intracellular) as well as extracellular DNA released by organisms through cell lysis, secretions, or waste (Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020). For practical drug discovery purposes, however, we focus on eDNA largely of microbial origin. Such eDNA typically comes from complex sources like soil, marine sediments, freshwater, extreme habitats like antarctic soils or deep-sea vents, and even host-associated environments such as plant rhizospheres and animal microbiomes. In all cases, the key point is that eDNA captures genetic information from uncultivated organisms and environments without requiring live cultures (Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020; Robinson, Piel and Sunagawa, 2021). This enables researchers to survey biodiversity and biosynthetic potential that cannot be accessed by plating or fermentation.
2.2 Relevance to Natural Product Discovery
The primary value of eDNA in drug discovery is its ability to unlock secondary metabolites from uncultivable microbes. An estimated, about 90-99% of microbial species cannot yet be cultured in the lab; their metabolic potential is hidden (Liu et al., 2022). eDNA sequencing provides a “window” into this microbial dark matter (Ling et al., 2015; Pawlowski, Apothéloz-Perret-Gentil and Altermatt, 2020). By sequencing all DNA in an environment, researchers can identify biosynthetic gene clusters (BGCs), which are contiguous sets of genes encoding multi-step pathways, that would otherwise go undetected (Montalbán-López et al., 2021). Such clusters often encode production of antibiotics, antifungals, anti-cancer agents, immunomodulators and other pharmaceuticals (Chakraborty, 2021; Sun et al., 2025; Bierhuizen, 2022).
Top UK Assignment Samples
Metagenomic analysis of eDNA thus expands the hunt for novel compounds far beyond traditional sources. It allows genome mining for BGCs in DNA fragments, even if the organism is uncultured (Nowak, 2023). For example, Jensen (2016) emphasizes that genome sequencing “has created unprecedented opportunities for natural product discovery and new insight into the diversity and distributions of natural product biosynthetic gene clusters”. Many new BGCs found via eDNA sequencing belong to taxa that are difficult or impossible to culture; such as unique actinobacteria, acidobacteria, proteobacteria, archaea, etc. (Waschulin et al., 2022; Mara et al., 2023; Dat et al., 2023; Seshadri et al., 2022). Accessing these clusters can reveal new classes of natural products with novel structures and activities.
2.3 Natural Product Biosynthesis
Secondary metabolites, commonly known as natural products, are the molecular outputs of BGCs (Zhgun, 2023). Key biosynthetic pathways include Nonribosomal Peptide Synthetases (NRPS), Polyketide Synthases (PKS), and Ribosomally synthesized and Post-translationally modified Peptides (RiPPs) (Mohan et al., 2024). NRPS and PKS are modular megasynthase enzymes that iteratively assemble amino acids for NRPS or acyl-CoA units for PKS into complex peptides and polyketides (Neves et al., 2022; Tippelt and Nett, 2021). RiPPs, in contrast, are peptides encoded by ribosomal genes and then chemically modified by cluster-encoded enzymes; forming classes like lanthipeptides, lasso peptides, thiopeptides (Montalbán-López et al., 2021). Together, NRPS, PKS and RiPP systems generate most of the clinically important microbial natural products such as vancomycin, erythromycin, streptomycin (NRPS/PKS-derived) and nisin (RiPP derived) (Prado-Alonso et al., 2022; Hobson, Chan and Wright, 2021; Krauß, 2024; Yuan et al., 2024).
Get Assignment Help for Top Subjects
In genomic terms, a BGC is a co-localized set of genes for enzyme assembly, regulation, and often resistance/self-protection. Identifying a BGC in an environmental genome or metagenome is a strong clue to the presence of a bioactive metabolite (Montalbán-López et al., 2021). BGCs provide a template for predictions of compound class: for instance, NRPS clusters suggest peptide antibiotics; PKS clusters suggest polyketides, some of which are anticancer or immunosuppressive agents; and RiPP clusters often imply small antimicrobial or signalling peptides (Fu et al., 2023; Kaniusaite et al., 2023; Flaherty, 2023). As Nowak et al. describe, BGCs are “groups of co-localized genes that collectively act to produce small molecules that confer some selective advantage to their producer” (Nowak, Hou and Owen, 2024). In practice, once a BGC is identified in eDNA via antiSMASH or similar, it can be prioritized for synthetic reconstruction or heterologous expression and screening, linking genotype to chemical phenotype (Nowak, 2023).
3. Methodologies in Environmental Metagenomics
3.1 Shotgun Metagenomic Sequencing
Shotgun metagenomic sequencing involves directly sequencing all DNA fragments in an environmental sample (Zhou, Liu and Yang, 2022). Short-read platforms like Illumina provide high accuracy and depth, while long-read platforms like PacBio HiFi, and Oxford Nanopore enable assembly of much longer contigs. In drug discovery, a hybrid approach is common: Illumina yields broad coverage of abundant genomes, whereas long reads span complete BGCs and resolve repeats. As an example, Van Goethem et al. (2021) performed deep long-read metagenomics on soil crust communities and recovered nearly 3,000 BGCs, including 712 full-length clusters. This demonstrated that long-read assemblies dramatically improve detection of intact pathways from uncultured microbes.
Shotgun metagenomes have been applied to complex habitats with rich chemistry. Marine sponge microbiomes, for instance, have yielded large numbers of novel BGCs. Nowak et al. assembled shotgun data from 16 sponge samples and obtained 643 high-quality MAGs containing over 2,670 BGCs (Nowak, Hou and Owen, 2024). Remarkably, 70.8% of these BGCs could be linked to a MAG (indicating taxonomic origin) (Nowak, Hou and Owen, 2024). These studies show that shotgun sequencing can reconstruct hundreds of microbial genomes (MAGs) and their biosynthetic clusters from a single sampling campaign, enabling broad surveys of secondary metabolite potential. Key tools include depth-of-coverage algorithms, binning pipelines, and specialized genome-mining software like antiSMASH for BGC detection, and BiG-SCAPE for clustering gene families (Blin et al., 2024; Yadav and Subramanian, 2024). With ever-cheaper sequencing, this “sequences first” strategy is now routine for any environmental sample suspected to harbor novel chemistry.
Feeling Overwhelmed By Your Assignment?
Get assistance from our PROFESSIONAL ASSIGNMENT WRITERS to receive 100% assured AI-free and high-quality documents on time, ensuring an A+ grade in all subjects.
3.2 Amplicon Sequencing and 16S rRNA Profiling
Amplicon sequencing, like of the 16S rRNA gene, is widely used in metagenomics for rapid taxonomic profiling of microbial communities (Zhang et al., 2023). It can identify which microbial taxa are present, and track community changes over time or space. However, 16S profiling alone cannot directly reveal biosynthetic gene content. The 16S gene is highly conserved and carries no information about secondary metabolism (Geng et al., 2022). Therefore, while 16S surveys help target interesting environments, like an environment rich in actinobacteria might be promising, they are insufficient alone for drug discovery (Nunes Ramos et al., 2025). In practice, 16S amplicon data is often used in tandem with metagenomics: for example, to confirm that a sample with many novel clades also has BGC-rich genomes from shotgun sequencing (Liu et al., 2021). But ultimately, detection of new antibiotics requires direct evidence of biosynthetic clusters or expressed activity, which comes from sequencing total DNA, not just marker genes.
3.3 Metagenome-Assembled Genomes (MAGs)
Metagenome-assembled genomes (MAGs) are reconstructed genomes derived from metagenomic data (Sebuta, 2021). After sequencing, bioinformaticians assemble reads into contigs, then “bin” contigs that belong to the same organism by patterns of coverage and nucleotide composition (Mallawaarachchi and Lin, 2022). MAGs allow recovery of near-complete genomes of uncultured microbes (Mirete et al., 2025). This is crucial for associating BGCs with specific taxa and for further analysis of entire pathways. For example, the sponge metagenomes mentioned above produced 643 MAGs (representing 510 species) from diverse phyla (Nowak, Hou and Owen, 2024). The BGCs found in those MAGs were then annotated and compared, revealing that many BGCs were highly novel relative to known databases.
Once MAGs are obtained, tools like antiSMASH scan them for BGCs; BiG-SCAPE or BiG-SLiCE can then cluster similar BGCs into gene cluster families (GCFs) to chart biosynthetic diversity (Kautsar et al., 2021). Genomic context from MAGs helps in designing expression strategies such as knowing codon usage, promoters, or regulatory genes (Long et al., 2021). A growing example: antiSMASH and the Minimum Information about a Biosynthetic Gene Cluster (MIBiG) database have enabled automated identification of thousands of environmental BGCs (Blin et al., 2019; Kautsar et al., 2020). MAG-based approaches, therefore, turn a metagenomic soup into discrete genomes, making genome mining and pathway reconstruction feasible.
3.4 Functional Metagenomics
Functional metagenomics takes the eDNA a step further by expressing it in a culturable host to detect activity. DNA extracted from the environment is cloned into expression vectors (often large-insert cosmids or BACs), and libraries are introduced into heterologous bacteria (commonly E. coli or Streptomyces hosts). The library clones are then screened for phenotypes such as antibiotic activity, enzymatic activity, or specific fluorescence. This phenotypic screening bypasses the need to predict function from sequence.
For example, Hover et al. used a targeted PCR approach to guide functional screening for novel NRPS antibiotics (Hover et al., 2018). They amplified conserved adenylation (AD) domain sequences from NRPS genes in a 2,000-soil eDNA library. The amplicon reads, NPSTs – Natural Product Sequence Tags, were analyzed by a bioinformatics pipeline eSNaPD to find unique clades (Hover et al., 2018). A particular soil was rich in NRPS tags related to calcium-dependent antibiotics; its eDNA was cloned into cosmids. Positive cosmids containing the entire malacidin biosynthetic gene cluster were isolated, assembled, and expressed in a laboratory host (Hover et al., 2018). The product, malacidin A, showed potent activity against multidrug-resistant Gram-positive pathogens.
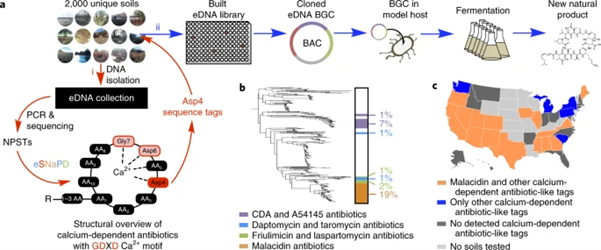
Figure 1: Pipeline for discovery of soil-derived malacidins (calcium-dependent antibiotics) using eDNA libraries, degenerate PCR, and heterologous expression.
Note: Conserved NRPS domains are PCR-amplified from environmental DNA, sequence tags (NPSTs) are analysed to identify novel clusters, cosmid libraries from promising samples are constructed to capture full BGCs, and the target BGC is engineered into a heterologous host for compound production and characterization (Hover et al., 2018).
Beyond PCR-guided methods, unbiased functional screens have also revealed activities. Libraries of random environmental DNA fragments can be plated on indicator media to find antibiotic-producing clones (Rebets et al., 2023). For enzymatic activities, coloured or fluorescent substrates can report hits. A key advantage of functional metagenomics is that it directly ties genotype to phenotype (Gantz et al., 2023). However, success depends on the heterologous host’s ability to express foreign genes: factors like codon usage, promoter recognition, and toxicity all matter. In practice, employing multiple hosts such as Streptomyces spp., E. coli, or yeast increases chances of heterologous expression (Berini, Marinelli and Binda, 2020; Wang et al., 2025). Functional metagenomics thus complements sequence-based methods by enabling discovery of metabolites whose gene clusters might be overlooked or mispredicted (Nam et al., 2023).
3.5 Synthetic Biology Approaches
Synthetic biology is now revolutionizing how eDNA-derived BGCs are exploited. Once a BGC sequence is known from MAGs or PCR tags, it can be chemically synthesized or PCR-assembled de novo, often with significant “refactoring” – reformatting the cluster with standardized parts like promoters, terminators, ribosome binding sites to optimize expression in a chosen host (Shao, Zhao and Zhao, 2013; Knight, 2003; Shetty, Endy and Knight, 2008; Gibson et al., 2009; Engler, Kandzia and Marillonnet, 2008). Li et al. emphasize that “BGC refactoring and heterologous expression provide a promising synthetic biology approach to NP discovery” (Li, MacIntyre and Brady, 2021). For example, promoters native to environmental microbes may not function in E. coli or yeast, so synthetic promoters or regulatory elements can be swapped in. Genes can be codon-optimized for the host, and large BGCs can be split into smaller operons for manageable assembly (Cook, 2021). Novel tools such as CRISPR-based recombineering, and DNA assembly techniques now allow multiplexed refactoring of entire clusters (Li, MacIntyre and Brady, 2021).
Custom biosynthetic pathway assembly also means one can mix-and-match enzymes: e.g. assemble NRPS modules from different eDNA sources to create new “unnatural” natural products (Huang, Stephan and Kries, 2021; Horinouchi, 2008; Skellam, Rajendran and Li, 2024). Beyond individual clusters, chassis organisms are being engineered with improved precursor supply like high CoA or amino acid pools, and minimized background metabolism to better express cryptic BGCs (Liu et al., 2022). Therefore, synthetic biology transforms raw eDNA sequences into executable blueprints for compound production, closing the gap between gene cluster and molecule.
Top Dissertation Topics UK
4. Case Studies: eDNA Successes in Drug Discovery
4.1 Teixobactin Discovery
A landmark success was the discovery of teixobactin, reported by Ling et al. in 2015. Using the iChip device, researchers incubated single uncultured soil bacteria in a diffusion chamber in situ, essentially cultivating bacteria in their natural soil habitat. One isolate, Eleftheria terrae, produced a novel antibiotic, teixobactin, that inhibits cell wall synthesis by binding lipid II and lipid III precursors (Rachedi, 2023). Crucially, teixobactin is potent against a broad range of Gram-positive pathogens including MRSA, Mycobacterium tuberculosis, & C. difficile and, in laboratory tests, no resistant mutants arose (Ling et al., 2015). This discovery exemplifies eDNA-driven bioprospecting: rather than traditional rich media, it used an environmental cultivation plug to access an otherwise uncultivable bacterium. Teixobactin validated the concept that unexplored microbial diversity can yield fundamentally new scaffolds. However, teixobactin is not yet in clinical use, highlighting the long development pathway from eDNA hit to drug.
4.2 Marine Microbiome: Salinosporamide A
Marine actinomycetes have long been a goldmine for natural products. The genus Salinispora, found in ocean sediments, produces an array of secondary metabolites. One of the most prominent is salinosporamide A (marizomib), a potent proteasome inhibitor with anticancer properties. As Jensen notes, Salinispora “maintains extraordinary levels of BGC diversity” and has served as a model for secondary metabolism (Jensen, 2016). The discovery of salinosporamide A predates high-throughput eDNA, but modern metagenomic mining in Salinispora and related taxa continues to yield new analogues and pathways. Whole-genome sequencing of a salinosporamide producer was a key step: it revealed the complete PKS/NRPS cluster responsible, enabling heterologous expression and pathway engineering (Carretero Molin, 2023). However, challenges remain; Salinispora BGCs often contain unusual enzymes like halogenases and Diels-Alderases that can be hard to express in the lab (Zhang, Moore and Tang, 2018). Moreover, complex marine compounds can be unstable. Thus, while eDNA/metagenomics accelerate discovery of marine antibiotic clusters, translating them into stable drug candidates – for example, large-scale production of marizomib; requires overcoming expression and scale-up hurdles.
4.3 Antarctic/Deep-Sea Extremophiles
Extreme environments like Antarctic soils, deep-sea vents, and hot springs harbour unique microbial communities with novel chemistries. Metagenomic studies of these habitats have begun to uncover new families of BGCs. For instance, long-read sequencing of Antarctic soil crusts and deep-sea sediments has revealed phylum-specific secondary metabolite genes that differ from temperate soils (Goethem et al., 2021). In one recent global ocean sequencing effort, Chen et al. generated more than 43,000 new marine MAGs and discovered a variety of antimicrobial peptide (AMP) genes from previously unknown microbial lineages (Chen et al., 2024). Among these were multiple novel ribosomal peptides and bacteriocins identified in polar and bathypelagic zones. These findings suggest that cold-adapted microbes may produce potent compounds like anti-freeze glycopeptides or cold-active antibiotics as chemical defence (Kochhar et al., 2022; Lopes et al., 2024). However, functional validation is ongoing: it is not yet clear how many of these eDNA-derived sequences encode pharmaceutically useful molecules. The main insight is that extremophiles expand the search space dramatically, but also present sampling challenges such as low biomass, and DNA degradation under extreme conditions (Rampelotto, 2024; Rawat, Chauhan and Pandey, 2024).
4.4 Bioprospecting in the Human Microbiome
The human microbiome, our resident bacteria, fungi, and viruses, is another reservoir of bioactive compounds. Genome mining of gut and skin microbiota has revealed numerous BGCs for ribosomal peptides such as thiopeptides, lanthipeptides, and nonribosomal peptides that modulate host physiology and microbial competition (Salamzade et al., 2023; Wu et al., 2025). For example, Donia and Fischbach (2015) showed that human gut genomes frequently encode thiopeptide antibiotics and other RiPPs that could influence gut ecology. A recent large-scale screen of human microbiome metagenomes found an extraordinary diversity of RiPP precursors, indicating novel peptide families (Zhang et al., 2025). Some of these may have anti-inflammatory or immunomodulatory effects in vivo. However, this area is fraught with ethical considerations. The extraction of eDNA from human-derived samples raises issues of consent, privacy, and benefit-sharing (de Groot, 2023). Research has highlighted a legacy of exploitation in microbiome studies: when unique microbes from indigenous populations are used without involving the source communities, it mirrors biopiracy (Bader et al., 2023). Thus, while the human microbiome could yield new therapeutics or biomarkers, any drug discovery efforts must navigate complex ethical and legal terrain, respecting privacy and equitable benefit-sharing.
4.5 Critical Reflection
The track record of eDNA-discovered compounds reaching the clinic is still developing. On the one hand, several notable natural products trace back to insights from genomic or metagenomic data. Salinosporamide A (marizomib) did progress to clinical trials for multiple myeloma, although its initial discovery was classical (Seyed and Ayesha, 2021). Teixobactin demonstrated proof of concept but has not yet become an approved drug (Lawrence et al., 2024). Many “hits” from eDNA (antibiotics identified in the lab) fail to translate due to issues like poor expression, toxicity to hosts, or unfavourable pharmacology (Ziemert, Alanjary and Weber, 2016; Medema and Fischbach, 2015). For instance, genetic sequences may encode molecules that are unstable or insoluble when produced in artificial hosts, or require unknown cofactors. Conversely, successes often hinge on integrated platforms: Ling et al. (2015) combined in situ cultivation with genomic screening, and Hover et al. (2018) merged PCR-based metagenomics with synthetic assembly. What has worked is the synergy of technological pipelines; metagenomics, cloning, and functional assay (Hover et al., 2018). What has failed most often are unaltered environmental clusters expressed “as is” in standard lab strains, or ambitious sampling without follow-up functional validation. Thus, eDNA drug discovery has delivered exciting lead structures but remains an early-stage field: many promising clusters are waiting for the molecular biology and development work needed to become therapies.
5. Challenges in eDNA-Based Drug Discovery
5.1 Technological
Despite advances, major technical hurdles persist. Environmental DNA is often sheared and degraded, yielding fragmented sequences (Naef et al., 2023). As a result, assemblies from short reads may break large BGCs into pieces, complicating reconstruction of intact pathways. Long-read sequencing mitigates this, but its higher error rates and costs can introduce misassemblies (Espinosa et al., 2024). Bioinformatic annotation is another issue: predicting function from sequence is not foolproof, so BGCs may be misclassified or overlooked (Ahmed, 2024). The greatest bottleneck, however, is heterologous expression. As Li et al. note, “a majority of NP biosynthetic gene clusters (BGCs) are functionally inaccessible under standard laboratory conditions” (Li, Maclntyre and Brady, 2021). Factors like codon bias differences, missing post-translational machinery, or metabolic imbalances mean that even a correctly assembled BGC often produces no detectable compound in a foreign host (Nowak, 2023). Engineering solutions such as promoter refactoring, chaperone co-expression, and precursor feeding are advancing, but this remains a rate-limiting step (Deng et al., 2022; Lv and Cai, 2025; Qu et al., 2023). The technological gaps are: acquiring long, accurate eDNA reads; correctly assembling and annotating megagenomes; and reliably expressing complex pathways. Each link in the pipeline has error margins that compound, making end-to-end success challenging.
5.2 Ecological and Sampling Issues
Environmental dynamics add another layer of complexity. Microbial communities fluctuate with season, weather, and ecological interactions, so a single eDNA sample is just a snapshot (Lin et al., 2024). Some BGCs may only be expressed under certain conditions like quorum, stress or only present in minor community members, making detection hit-or-miss. DNA from extreme or deep habitats may degrade, like in UV in surface water and DNases in soil, biasing what is recoverable (Ballmer, McNeill and Deiner; 2024; Joseph et al., 2022). There is also sampling bias: easily reachable environments such as agricultural soils or shallow waters are oversampled, while remote biomes such as deep-sea trenches or uncontacted ecosystems remain underexplored (Hughes et al., 2021). Low-biomass environments like desert soils or cryoconite yield little DNA (Simon et al., 2023). These issues mean that metagenomic surveys can misrepresent true diversity. Statistically robust sampling and replication, both spatial and temporal, are needed but increase cost. Ultimately, eDNA data must be interpreted with an understanding of these ecological constraints: absence of evidence is not evidence of absence.
5.3 Bioethical and Legal Considerations
The collection and use of eDNA raise serious bioethical and legal issues. The Nagoya Protocol on Access and Benefit-Sharing (ABS) mandates that genetic resources and their digital sequence derivatives should be accessed with prior informed consent and fair compensation to source countries or communities (Akpoviri, Baharum and Zainol, 2023; Pisupati and Sathyarajan, 2022). However, eDNA blurs these lines: researchers may sequence thousands of organisms from an environmental sample, some of which could be native or endemic to a specific region. The Convention on Biological Diversity has only recently begun to address “digital sequence information” (DSI) in global agreements (CBD, n,d,). In 2022, the UNCBD decided to establish a multilateral fund (the “Cali Fund”) to equitably share benefits from DSI use (CBD, 2022). Until such frameworks are fully operational, international eDNA projects risk noncompliance or perceived biopiracy. Moreover, indigenous rights are paramount: as Bader et al. highlight, microbiome research has historically “failed to include Indigenous people in knowledge co-production or benefit, perpetuating a legacy of intellectual and material extraction” (Bader et al., 2023). These concerns extend to human microbiome samples as well, where issues of consent and privacy are acute. Therefore, ethical eDNA bioprospecting requires transparent benefit-sharing agreements, community involvement, and respect for biodiversity heritage.
5.4 Data Management and Reproducibility
eDNA projects generate massive data sets that strain current data management infrastructure. Raw reads and assembled metagenomes occupy terabytes, requiring powerful computation for storage and analysis. Uniform annotation is lacking: different groups use varying pipelines, making cross-study comparisons difficult. There is a need for standardized metadata and repositories. Existing resources like IMG-ABC (Integrated Microbial Genomes Atlas of BGCs) and antiSMASH databases curate BGCs, but an international repository specifically for environmental BGC sequences with rich ecological metadata would be transformative (Bağcı et al., 2025). The lack of standardized protocols for eDNA sampling, extraction, and sequencing also hinders reproducibility. Recently, initiatives like Genomic Standards Consortium’s MIMS/MIGS have attempted to standardize metagenome metadata, and ISO committees are developing eDNA sampling guidelines (Mukherjee et al., 2023; Theroux et al., 2024). For credible drug discovery, the field must converge on best practices so that findings (e.g. “BGC X was found in soil sample Y”) can be independently validated and built upon.
6. Enhancing eDNA Drug Discovery with AI and Bioinformatics
6.1 Machine Learning in BGC Prediction
Artificial intelligence is increasingly integral to genome mining. Traditional BGC identification like antiSMASH relies on profile Hidden Markov Models of known enzyme domains (Blin et al., 2025). Newer deep learning tools like DeepBGC use neural networks to scan genomes for BGC signatures, reducing false positives and generalizing to novel cluster types (Liu, Li and Li, 2022). For example, Hannigan et al.’s (2019) DeepBGC achieved better detection of partial or divergent NRPS/PKS clusters. In parallel, ML models have been applied to predict the chemical structures or activities of encoded metabolites. PRISM is a tool that analyses BGC sequences and suggests possible chemical substructuresMost of the time, they are taught using databases that have known pairs of BGC-compounds (MIBiG) (Zdouc et al., 2025). If the training set is bigger, ML is able to discover more distant relationships. Also, ML models that rely on bioactivity data and antiSMASH outcomes can highlight clusters that have antibacterial or anticancer lead-like properties (Li et al., 2023; Hannigan et al., 2019; Skinnider et al., 2017). In the future, scientists will be able to use machine learning to quickly find the clusters that should be tested.
6.2 AI-Driven Pathway Refactoring
AI can be used to direct the process in synthetic biology. They can guide in enhancing a gene cluster’s expression by choosing proper promoters, adjusting operons and predicting the best codon usage (Hashemi et al., 2021; Torkamanian-Afshar et al., 2021; Yaraguppi et al., 2021). With computational models, it is possible to simulate the metabolic activity of a chosen host to find out if there are any issues or toxicity. For instance, machine learning could help determine if a refactored NRPS cluster would be too much for E. coli and it could also recommend host engineering such as removing competing pathways (Pearcy et al., 2021). These AI-driven design tools reduce trial-and-error in the lab. In practice, a “closed-loop” system is envisioned: AI designs a synthetic gene cluster, it is synthesized and expressed, lab robotics assays the product, and the data feedback to refine the model. This tight integration accelerates conversion of eDNA sequences into compounds.
6.3 Virtual Screening and Target Prediction
Once candidate compounds or their predicted structures are in hand, computational methods can pre-assess their potential. Virtual docking can model how an eDNA-derived compound might bind human protein targets such as bacterial enzymes and cancer cell receptors, informing likely mechanism of action (Narykov et al., 2024; Agu et al., 2023). Multi-omics integration like combining metagenome data with transcriptomics or metabolomics can also illuminate which pathways are active in situ and how compounds affect communities (Arıkan and Muth, 2023). Tools like GNPS (Global Natural Products Social molecular networking) allow matching of mass spectra to predicted BGCs (Crüsemann, 2021). AI-enabled in silico screening can, therefore, triage hits before costly wet-lab assays, focusing resources on the most promising leads.
6.4 Cloud Platforms and Open-Source Tools
The collaborative nature of eDNA discovery is amplified by cloud-based bioinformatics. Databases like IMG-ABC (JGI), MIBiG (Sparte Inc./CAS), and MiBIG (Medema group) provide annotated BGC collections. AntiSMASH continues to be updated (v7, 8) with more compound classes and better rule sets. Global networks like EBI’s MGnify host thousands of public metagenomes. Open platforms like GNPS for metabolomics and QIITA for microbiome data allow cross-lab sharing of raw and processed data. Use of standardized file formats such as FASTQ, GenBank, SBOL, and containerized workflows like using Biocontainers and Galaxy improves reproducibility. The democratization of tools (many of which are free or have academic licenses) enables smaller labs to participate in eDNA research. Importantly, global consortia are emerging to coordinate eDNA efforts (akin to the Earth Microbiome Project), recognizing that data sharing and interoperability are key to progress (Chen et al., 2024).
7. Strategic Recommendations for Future Advancements
7.1 Future Vision: Closed-Loop Discovery
Looking ahead, the goal is a largely automated, closed-loop discovery pipeline. In this vision:
- eDNA sample is collected and sequenced;
- AI genome mining identifies candidate BGCs and predicts their chemical scaffolds;
- automated DNA synthesis and cloning machinery refactors the clusters into expression vectors;
- robotic fermentation or cell-free expression produces compounds;
- high-throughput bioassays (antimicrobial panels, cell-based screens) test activity;
- all data flow back into AI models to refine predictions.
Such “smart bioprospecting” would greatly shorten the cycle from sample to hit. Integrating Internet of Things (IoT) sensors for real-time sampling metadata and blockchain for secure benefit-sharing records could further systematize the field. Although partly aspirational, elements of this vision are already in place and represent a strategic goal for the field.
7.2 Recommendations
- Global eDNA Repositories with Ethical Access Protocols: Establish international databases for eDNA sequences and associated metadata including geo-location, sampling context, and legal status. These should align with Nagoya ABS rules and promote open science. For example, an initiative analogous to the International Nucleotide Sequence Database Collaboration (INSDC) but tailored for BGCs and metagenomes would ensure broad accessibility. Ensure that benefit-sharing mechanisms like the CBD’s “Cali Fund” for DSI are integrated so that source countries and communities receive fair returns. Partnerships with frameworks like the International Microbiome Initiative could govern governance.
- Standardisation of eDNA Sampling and Processing: Develop ISO-like standards for eDNA workflows (from sample collection and preservation to sequencing and annotation). This includes protocols for avoiding contamination, quantifying DNA yield, and curating metadata. Cross-lab proficiency tests should be held to benchmark performance. Standardization will improve data comparability and reproducibility, enabling meta-analyses across studies.
- Investment in Synthetic Biology for Cryptic BGCs: Allocate resources to synthetic biology platforms dedicated to eDNA clusters. This means expanding libraries of chassis strains like Streptomyces, yeast, Bacillus, cell-free systems etc. optimized for NP expression, and building modular parts like promoters & RBSs validated in these hosts. Public-private partnerships could fund core facilities that handle large-scale BGC refactoring and screening, reducing redundancy across labs.
- Enhanced AI–Bioinformatics Collaboration Platforms: Foster collaborative projects that merge drug discovery with AI. For instance, integrated platforms could combine ML-based target prediction for drug-likeness and ADMET properties with BGC mining, so that compounds are evaluated holistically. Encourage open-source development of AI tools for BGC annotation and compound prediction. Workshops and hackathons bringing together microbiologists, chemists, and data scientists will cross-pollinate ideas and standardize tools.
8. Conclusion
Environmental DNA sequencing is revolutionizing natural product drug discovery. By tapping into the vast genetic reservoir of uncultivated microbes, eDNA approaches enable access to novel bioactive compound families that would otherwise remain hidden. The core insight is that the Earth’s microbial DNA is an enormous library of potential drug leads. Realizing its value requires an integrated strategy: advanced sequencing technologies to obtain high-quality metagenomes; powerful bioinformatic or AI tools to identify and prioritize biosynthetic gene clusters; ethical global sampling that respects ABS regulations; and synthetic biology to turn sequences into molecules. When these components are combined, along with automated screening, eDNA moves from being a research tool to a next-generation platform for drug discovery. As Rosenzweig et al. conclude, ongoing technological improvements will “dramatically increase the rate at which antibiotics are discovered from metagenomes” (Rosenzweig, Burian and Brady, 2023). In this sense, eDNA is not merely incremental innovation; it is a paradigm shift towards decentralized, sustainable bioprospecting. The future of antibiotic and natural product discovery lies in this intelligent, data-driven exploration of our biosphere’s genetic bounty.
References
Agu, P.C., Afiukwa, C.A., Orji, O.U., Ezeh, E.M., Ofoke, I.H., Ogbu, C.O., Ugwuja, E.I. and Aja, P.M., 2023. Molecular docking as a tool for the discovery of molecular targets of nutraceuticals in diseases management. Scientific Reports, 13, Article 12989. https://doi.org/10.1038/s41598-023-40160-2.
Ahmed, F., 2024. Genomics and bioinformatics: integrating data for better genetic insights. Frontiers in Biotechnology and Genetics, 1(2), pp.126–146. Available at: https://sprcopen.org/FBG/article/view/74 [Accessed 6 Jun. 2025].
Akpoviri, F.I., Baharum, S.N. and Zainol, Z.A., 2023. Digital sequence information and the access and benefit-sharing obligation of the Convention on Biological Diversity. Nanoethics, 17(1), p.1. https://doi.org/10.1007/s11569-023-00436-3.
Al Aboud, N.M. (2024) ‘Unlocking the genetic potential: Strategies for enhancing secondary metabolite biosynthesis in plants’, Journal of the Saudi Society of Agricultural Sciences, 23, pp. 1–10. Available at: https://doi.org/10.1016/j.jssas.2024.06.004.
Arıkan, M. and Muth, T., 2023. Integrated multi-omics analyses of microbial communities: a review of the current state and future directions. Molecular Omics, 19(4), pp.361–375. https://doi.org/10.1039/D3MO00089C.
Bader, A.C., Van Zuylen, E.M., Handsley-Davis, M., Alegado, R.A., Benezra, A., Pollet, R.M., Ehau-Taumaunu, H., Weyrich, L.S. and Anderson, M.Z. (2023) ‘A relational framework for microbiome research with Indigenous communities’, Nature Microbiology, 8(10), pp. 1768–1776. Available at: https://doi.org/10.1038/s41564-023-01471-2.
Bağcı, C., Nuhamunada, M., Goyat, H., Ladanyi, C., Sehnal, L., Blin, K., Kautsar, S.A., Tagirdzhanov, A., Gurevich, A., Mantri, S., von Mering, C., Udwary, D., Medema, M.H., Weber, T. and Ziemert, N., 2025. BGC Atlas: a web resource for exploring the global chemical diversity encoded in bacterial genomes. Nucleic Acids Research, 53(D1), pp.D618–D624. https://doi.org/10.1093/nar/gkae953.
Ballmer, E., McNeill, K. and Deiner, K., 2024. Potential role of photochemistry in environmental DNA degradation. Environmental Science & Technology Letters, 11(12). https://doi.org/10.1021/acs.estlett.4c00704.
Berini, F., Marinelli, F. and Binda, E. (2020) ‘Streptomycetes: attractive hosts for recombinant protein production’, Frontiers in Microbiology, 11, Article 1958. Available at: https://doi.org/10.3389/fmicb.2020.01958.
Bierhuizen, D. (2022) Antifungal discovery: Unlocking the hidden potential of fungal genomes. Master’s thesis. Utrecht University. Available at: https://studenttheses.uu.nl/handle/20.500.12932/41613 (Accessed: 6 June 2025).
Blin, K., Shaw, S., Steinke, K., Villebro, R., Ziemert, N., Lee, S.Y., Medema, M.H. and Weber, T. (2019) ‘antiSMASH 5.0: updates to the secondary metabolite genome mining pipeline’, Nucleic Acids Research, 47(W1), pp.W81–W87. Available at: https://doi.org/10.1093/nar/gkz310.
Blin, K., Shaw, S., Vader, L., Szenei, J., Reitz, Z.L., Augustijn, H.E., Cediel-Becerra, J.D.D., de Crécy-Lagard, V., Koetsier, R.A., Williams, S.E., et al. (2024) ‘antiSMASH 8.0: extended gene cluster detection capabilities and analyses of chemistry, enzymology, and regulation’, Nucleic Acids Research, gkaf334. Available at: https://doi.org/10.1093/nar/gkaf334.
Carretero Molina, D. (2023) Expanding the chemical space of microbial specialized metabolites: structure elucidation and biosynthesis of novel bioactive natural products from actinomycetes. PhD thesis. Universidad de Granada. Available at: https://hdl.handle.net/10481/89254 (Accessed: 6 June 2025).
CBD, 2022. Decision 15/9: Digital sequence information on genetic resources. [online] Conference of the Parties to the CBD, COP-15, Montreal. Available at: https://www.cbd.int/doc/decisions/cop-15/cop-15-dec-09-en.pdf [Accessed 6 Jun. 2025].
CBD, n.d. Digital sequence information on genetic resources. [online] Convention on Biological Diversity. Available at: https://www.cbd.int/dsi-gr [Accessed 6 Jun. 2025].
Chakraborty, P. (2021) ‘Gene cluster from plant to microbes: Their role in genome architecture, organism’s development, specialized metabolism and drug discovery’, Biochimie, 194, pp. 89–102. Available at: https://doi.org/10.1016/j.biochi.2021.12.001.
Chen, J., Jia, Y., Sun, Y., Liu, K., Zhou, C., Liu, C., Li, D., Liu, G., Zhang, C., Yang, T., Huang, L., Zhuang, Y., Wang, D., Xu, D., Zhong, Q., Guo, Y., Li, A., Seim, I., Jiang, L., Wang, L., Lee, S.M.Y., Liu, Y., Wang, D., Zhang, G., Liu, S., Wei, X., Yue, Z., Zheng, S., Shen, X., Wang, S., Qi, C., Chen, J., Ye, C., Zhao, F., Wang, J., Fan, J., Li, B., Sun, J., Jia, X., Xia, Z., Zhang, H., Liu, J., Zheng, Y., Liu, X., Wang, J., Yang, H., Kristiansen, K., Xu, X., Mock, T., Li, S., Zhang, W. and Fan, G. (2024) ‘Global marine microbial diversity and its potential in bioprospecting’, Nature, 633(12), pp. 371–379. Available at: https://doi.org/10.1038/s41586-024-07891-2.
Cook, T.B., 2021. Expressing and engineering natural product enzymes in bacterial hosts. PhD thesis. University of Wisconsin-Madison. Available at: https://www.proquest.com/openview/6f81b1224d3c563a2126309a7bd03747/1?pq-origsite=gscholar&cbl=18750&diss=y [Accessed 6 June 2025].
Crüsemann, M., 2021. Coupling mass spectral and genomic information to improve bacterial natural product discovery workflows. Marine Drugs, 19(3), p.142. https://doi.org/10.3390/md19030142.
Dat, T.T.H., Steinert, G., Nguyen, T.K.C., Cuong, P.V., Smidt, H. and Sipkema, D. (2023) ‘Diversity of bacterial secondary metabolite biosynthetic gene clusters in three Vietnamese sponges’, Marine Drugs, 21(1), Article 29. Available at: https://doi.org/10.3390/md21010029.
de Groot, N.F., 2023. Capturing human environmental DNA: ethical challenges. Digital Society, 2(3), pp.225–239. https://doi.org/10.1007/s44206-023-00077-9.
Deng, C., Wu, Y., Lv, X., Li, J., Liu, Y., Du, G., Chen, J. and Liu, L., 2022. Refactoring transcription factors for metabolic engineering. Biotechnology Advances, 60, p.107935. https://doi.org/10.1016/j.biotechadv.2022.107935.
Donia, M.S. and Fischbach, M.A., 2015. Small molecules from the human microbiota. Science, 349(6246), p.1254766. https://doi.org/10.1126/science.1254766.
Engler, C., Kandzia, R. and Marillonnet, S., 2008. A one pot, one step, precision cloning method with high throughput capability. PLoS ONE, 3(11), e3647. https://doi.org/10.1371/journal.pone.0003647.
Espinosa, E., Bautista, R., Larrosa, R. and Plata, O., 2024. Advancements in long-read genome sequencing technologies and algorithms. Genomics, 116, 110842. https://doi.org/10.1016/j.ygeno.2024.110842.
Flaherty, H.R. (2023) Identification of novel biosynthetic gene clusters encoding for polyketide/NRPs-producing chemotherapeutic compounds from marine-derived Streptomyces hygroscopicus from a marine sanctuary. Undergraduate honours thesis. University of New Hampshire. Available at: https://scholars.unh.edu/honors/765 (Accessed: 6 June 2025).
Fu, Y., Xu, Y., Ruijne, F. and Kuipers, O.P. (2023) ‘Engineering lanthipeptides by introducing a large variety of RiPP modifications to obtain new-to-nature bioactive peptides’, FEMS Microbiology Reviews, 47(3), pp. 1–22. Available at: https://doi.org/10.1093/femsre/fuad017.
Gantz, M., Neun, S., Medcalf, E.J., van Vliet, L.D. and Hollfelder, F. (2023) ‘Ultrahigh-throughput enzyme engineering and discovery in in vitro compartments’, Chemical Reviews, 123(9), pp. 5951–6000. Available at: https://doi.org/10.1021/acs.chemrev.2c00910.
Geng, J., Sui, Z., Dou, W., Miao, Y., Wang, T., Wei, X., Chen, S., Zhang, Z., Xiao, J. and Huang, D. (2022) ‘16S rRNA gene sequencing reveals specific gut microbes common to medicinal insects’, Frontiers in Microbiology, 13, Article 892767. Available at: https://doi.org/10.3389/fmicb.2022.892767.
Gibson, D.G. et al., 2009. Enzymatic assembly of DNA molecules up to several hundred kilobases. Nature Methods, 6(5), pp.343–345. https://doi.org/10.1038/nmeth.1318.
Hannigan, G.D., Prihoda, D., Palicka, A., Soukup, J., Klempir, O., Rampula, L., Durcak, J., Wurst, M., Kotowski, J., Chang, D., Wang, R., Piizzi, G., Temesi, G., Hazuda, D.J., Woelk, C.H. and Bitton, D.A., 2019. A deep learning genome-mining strategy for biosynthetic gene cluster prediction. Nucleic Acids Research, 47(18), p.e110. https://doi.org/10.1093/nar/gkz654.
Hashemi, Z.S., Zarei, M., Karami Fath, M., Ganji, M., Shahrabi Farahani, M., Afsharnouri, F., Pourzardosht, N., Khalesi, B., Jahangiri, A., Rahbar, M.R. and Khalili, S., 2021. In silico approaches for the design and optimization of interfering peptides against protein–protein interactions. Frontiers in Molecular Biosciences, 8, p.669431. https://doi.org/10.3389/fmolb.2021.669431.
Hobson, C., Chan, A.N. and Wright, G.D. (2021) ‘The antibiotic resistome: a guide for the discovery of natural products as antimicrobial agents’, Chemical Reviews, 121(6), pp. 3464–3494. Available at: https://doi.org/10.1021/acs.chemrev.0c01214.
Horinouchi, S. (2008) ‘Combinatorial biosynthesis of non-bacterial and unnatural flavonoids, stilbenoids and curcuminoids by microorganisms’, Journal of Antibiotics, 61(12), pp. 709–728. Available at: https://doi.org/10.1038/ja.2008.85.
Hover, B.M., Kim, S.-H., Katz, M., Charlop-Powers, Z., Owen, J.G., Ternei, M.A., Maniko, J., Estrela, A.B., Molina, H., Park, S., Perlin, D.S. and Brady, S.F. (2018) ‘Culture-independent discovery of the malacidins as calcium-dependent antibiotics with activity against multidrug-resistant Gram-positive pathogens’, Nature Microbiology, 3(4), pp. 415–422. Available at: https://doi.org/10.1038/s41564-018-0110-1.
Huang, H.-M., Stephan, P. and Kries, H. (2021) ‘Engineering DNA-templated nonribosomal peptide synthesis’, Cell Chemical Biology, 28(2), pp. 221–227.e7. Available at: https://doi.org/10.1016/j.chembiol.2020.11.004.
Hughes, A.C., Orr, M.C., Ma, K., Costello, M.J., Waller, J., Provoost, P., Yang, Q., Zhu, C. and Qiao, H., 2021. Sampling biases shape our view of the natural world. Ecography, 44(9), pp.1259–1269. https://doi.org/10.1111/ecog.05926.
Jensen, P.R. (2016) ‘Natural products and the gene cluster revolution’, Trends in Microbiology, 24(12), pp. 968–977. Available at: https://doi.org/10.1016/j.tim.2016.07.006.
Joseph, C., Faiq, M.E., Li, Z. and Chen, G., 2022. Persistence and degradation dynamics of eDNA affected by environmental factors in aquatic ecosystems. Hydrobiologia, 849, pp.4119–4133. https://doi.org/10.1007/s10750-022-04959-w.
Kaniusaite, M., Tailhades, J., Kittilä, T., Fage, C.D., Goode, R.J.A., Schittenhelm, R.B. and Cryle, M.J. (2023) ‘Understanding the early stages of peptide formation during the biosynthesis of teicoplanin and related glycopeptide antibiotics’, The FEBS Journal, 290(19), pp. 5331–5347. Available at: https://doi.org/10.1111/febs.15350.
Kautsar, S.A., Blin, K., Shaw, S., Navarro-Muñoz, J.C., Terlouw, B.R., van der Hooft, J.J.J., van Santen, J.A., Tracanna, V., Suarez Duran, H.G., Pascal Andreu, V., Selem-Mojica, N., Alanjary, M., Robinson, S.L., Lund, G., Epstein, S.C., Sisto, A.C., Charkoudian, L.K., Collemare, J., Linington, R.G., Weber, T. and Medema, M.H. (2020) ‘MIBiG 2.0: a repository for biosynthetic gene clusters of known function’, Nucleic Acids Research, 48(D1), pp.D454–D458. Available at: https://doi.org/10.1093/nar/gkz882.
Kautsar, S.A., van der Hooft, J.J.J., de Ridder, D. and Medema, M.H. (2021) ‘BiG-SLiCE: a highly scalable tool maps the diversity of 1.2 million biosynthetic gene clusters’, GigaScience, 10(1), giaa154. Available at: https://doi.org/10.1093/gigascience/giaa154.
Knight, T.F., 2003. Idempotent vector design for standard assembly of biobricks. MIT Synthetic Biology Working Group Technical Reports. Available at: https://hdl.handle.net/1721.1/21168 [Accessed 6 June 2025].
Kochhar, N., I.K, K., Shrivastava, S., Ghosh, A., Rawat, V.S., Sodhi, K.K. and Kumar, M., 2022. Perspectives on the microorganism of extreme environments and their applications. Current Research in Microbial Sciences, 3, p.100134. Available at: https://doi.org/10.1016/j.crmicr.2022.100134 [Accessed 6 Jun. 2025].
Krauß, S. (2024) Staphylococcal antimicrobial biosynthetic gene clusters and their impact on bacterial fitness. Doctoral dissertation. Universität Tübingen. Available at: http://dx.doi.org/10.15496/publikation-73037.
Lawrence, W.S., Peel, J.E., de Winter, R., Ling, L.L., Nitti, A.G., Peoples, A.J., Shukla, R., MacGillavry, H.D., Heine, H.S., Hensel, M.E., Whorton, E.B., Weingarth, M., Lewis, K. and Hughes, D.E., 2024. Teixobactin: A resistance-evading antibiotic for treating anthrax. ACS Infectious Diseases, [online] https://doi.org/10.1021/acsinfecdis.4c00835.
Li, L., MacIntyre, L.W. and Brady, S.F. (2021) ‘Refactoring biosynthetic gene clusters for heterologous production of microbial natural products’, Current Opinion in Biotechnology, 69, pp. 103–110. Available at: https://doi.org/10.1016/j.copbio.2020.12.011.
Li, Y., Zhang, L., Zhang, J., Liu, Y. and Shen, B., 2023. Machine learning-enabled genome mining for natural product discovery. Nature Product Reports, 40(11), pp.1890–1909. https://doi.org/10.1039/D3NP00053H.
Lin, X., Li, K., Zhao, H., Gao, Y., Zhang, Z., Wang, L., Wang, X., Sanganyado, E., Zheng, Z., Gutang, Q., Liu, S., Li, P., Yan, X., Chen, Z., Lin, J. and Liu, W., 2024. Seasonal changes of plankton community and its influencing factors in subtropical coastal marine areas revealed by eDNA-based network analysis. Frontiers in Marine Science, 11, 1416359. https://doi.org/10.3389/fmars.2024.1416359.
Ling, L.L., Schneider, T., Peoples, A.J., Spoering, A.L., Engels, I., Conlon, B.P., Mueller, A., Schäberle, T.F., Hughes, D.E., Epstein, S., Jones, M., Lazarides, L., Steadman, V.A., Cohen, D.R., Felix, C.R., Fetterman, K.A., Millett, W.P., Nitti, A.G., Zullo, A.M., Chen, C. and Lewis, K. (2015) ‘A new antibiotic kills pathogens without detectable resistance’, Nature, 517(7535), pp. 455–459. Available at: https://doi.org/10.1038/nature14098.
Liu, J., Wang, X., Dai, G., Zhang, Y. and Bian, X. (2022). Microbial chassis engineering drives heterologous production of complex secondary metabolites. Biotechnology Advances, 59, 107966. Available at: https://doi.org/10.1016/j.biotechadv.2022.107966 (Accessed: 6 June 2025).
Liu, M., Li, Y. and Li, H., 2022. Deep learning to predict the biosynthetic gene clusters in bacterial genomes. Journal of Molecular Biology, 434(22), p.167597. https://doi.org/10.1016/j.jmb.2022.167597.
Liu, S., Moon, C.D., Zheng, N., Huws, S., Zhao, S. and Wang, J. (2022) ‘Opportunities and challenges of using metagenomic data to bring uncultured microbes into cultivation’, Microbiome, 10, Article 76. Available at: https://doi.org/10.1186/s40168-022-01272-5.
Liu, Y.X., Qin, Y., Chen, T., Lu, M., Qian, X., Guo, X. and Bai, Y. (2021) ‘A practical guide to amplicon and metagenomic analysis of microbiome data’, Protein & Cell, 12(5), pp.315–330. Available at: https://doi.org/10.1007/s13238-020-00724-8.
Long, A.M., Hou, S., Ignacio-Espinoza, J.C. and Fuhrman, J.A. (2021) ‘Benchmarking microbial growth rate predictions from metagenomes’, The ISME Journal, 15(1), pp.183–195. Available at: https://doi.org/10.1038/s41396-020-00773-1.
Lopes, J.C., Kinasz, C.T., Luiz, A.M.C., Kreusch, M.G. and Duarte, R.T.D., 2024. Frost fighters: unveiling the potential of microbial antifreeze proteins in biotech innovation. Journal of Applied Microbiology, 135(6), lxae140. Available at: https://doi.org/10.1093/jambio/lxae140 [Accessed 6 Jun. 2025].
Lv, W. and Cai, M., 2025. Advancing recombinant protein expression in Komagataella phaffii: opportunities and challenges. FEMS Yeast Research, 25, foaf010. https://doi.org/10.1093/femsyr/foaf010.
Mallawaarachchi, V. and Lin, Y. (2022) ‘Accurate binning of metagenomic contigs using composition, coverage, and assembly graphs’, Journal of Computational Biology, 29(11), pp.1247–1259. Available at: https://doi.org/10.1089/cmb.2022.0262.
Mara, P., Geller-McGrath, D., Edgcomb, V., Beaudoin, D., Morono, Y. and Teske, A. (2023) ‘Metagenomic profiles of archaea and bacteria within thermal and geochemical gradients of the Guaymas Basin deep subsurface’, Nature Communications, 14, Article 7768. Available at: https://doi.org/10.1038/s41467-023-43296-x.
Medema, M.H. and Fischbach, M.A., 2015. Computational approaches to natural product discovery. Nature Chemical Biology, 11(9), pp.639–648. https://doi.org/10.1038/nchembio.1884.
Mirete, S., Sánchez-Costa, M., Díaz-Rullo, J., González de Figueras, C., Martínez-Rodríguez, P. and González-Pastor, J.E. (2025) ‘Metagenome-assembled genomes (MAGs): advances, challenges, and ecological insights’, Microorganisms, 13(5), Article 985. Available at: https://doi.org/10.3390/microorganisms13050985.
Mohan, M.S., Salim, S.A., Pakhira, P. and Busi, S. (2024) ‘Microbial production of polyketides and non-ribosomal peptides and their applications’, in Kothari, V., Ray, S. and Kumar, P. (eds.) Microbial products for health and nutrition. Singapore: Springer, pp. [insert page numbers]. Available at: https://doi.org/10.1007/978-981-97-4235-6_15.
Montalbán-López, M., Scott, T.A., Ramesh, S., Rahman, I.R., Van Heel, A.J., Viel, J.H., Bandarian, V., Dittmann, E., Genilloud, O., Goto, Y., Burgos, M.J.G., Hill, C., Kim, S., Koehnke, J., Latham, J.A., Link, A.J., Martínez, B., Nair, S.K., Nicolet, Y., Rebuffat, S., Sahl, H.-G., Sareen, D., Schmidt, E.W., Schmitt, L., Severinov, K., Süssmuth, R.D., Truman, A.W., Wang, H., Weng, J.-K., van Wezel, G.P., Zhang, Q., Zhong, J., Piel, J., Mitchell, D.A., Kuipers, O.P. and van der Donk, W.A. (2021) ‘New developments in RiPP discovery, enzymology and engineering’, Natural Product Reports, 38(1), pp. 130–239. Available at: https://doi.org/10.1039/D0NP00027B.
Montalbán-López, M., Scott, T.A., Ramesh, S., Rahman, I.R., Van Heel, A.J., Viel, J.H., Bandarian, V., Dittmann, E., Genilloud, O., Goto, Y., Burgos, M.J.G., Hill, C., Kim, S., Koehnke, J., Latham, J.A., Link, A.J., Martínez, B., Nair, S.K., Nicolet, Y., Rebuffat, S., Sahl, H.-G., Sareen, D., Schmidt, E.W., Schmitt, L., Severinov, K., Süssmuth, R.D., Truman, A.W., Wang, H., Weng, J.-K., van Wezel, G.P., Zhang, Q., Zhong, J., Piel, J., Mitchell, D.A., Kuipers, O.P. and van der Donk, W.A. (2021) ‘New developments in RiPP discovery, enzymology and engineering’, Natural Product Reports, 38(1), pp. 130–239. Available at: https://doi.org/10.1039/D0NP00027B.
Mukherjee, A., D’Ugo, E., Giuseppetti, R., Magurano, F. and Cotter, P.D., 2023. Chapter 5 – Metagenomic approaches for understanding microbial communities in contaminated environments: Bioinformatic tools, case studies and future outlook. In: P. Kumar and H. Balaram, eds. Environmental Metagenomics: Current Advances, Challenges and Future Perspectives. 1st ed. Amsterdam: Elsevier, pp.89–113. https://doi.org/10.1016/B978-0-323-96113-4.00003-2.
Naef, T., Besnard, A.-L., Lehnen, L., Petit, E.J., van Schaik, J. and Puechmaille, S.J., 2023. How to quantify factors degrading DNA in the environment and predict degradation for effective sampling design. Ecology and Evolution, 13(4), e0414. https://doi.org/10.1002/edn3.414.
Nam, N.N., Do, H.D.K., Trinh, K.T.L. and Lee, N.Y. (2023) ‘Metagenomics: An effective approach for exploring microbial diversity and functions’, Foods, 12(11), p.2140. Available at: https://doi.org/10.3390/foods12112140.
Narykov, O., Zhu, Y., Brettin, T., Evrard, Y.A., Partin, A., Shukla, M., Xia, F., Clyde, A., Vasanthakumari, P., Doroshow, J.H. and Stevens, R.L., 2024. Integration of computational docking into anti-cancer drug response prediction models. Cancers, 16(1), p.50. https://doi.org/10.3390/cancers16010050.
Neves, R.P.P., Ferreira, P., Medina, F.E., Almeida, R., Fernandes, C., Moreira, A.F., Carvalho, J.M., Barros, M.T. and Fonseca, M.R. (2022) ‘Engineering of PKS megaenzymes—A promising way to biosynthesize high-value active molecules’, Topics in Catalysis, 65, pp. 544–562. Available at: https://doi.org/10.1007/s11244-021-01490-5.
Nowak, V. (2023) New methods for the discovery of natural products from understudied and uncultivated bacterial phyla. Doctoral dissertation. Open Access Te Herenga Waka – Victoria University of Wellington. Available at: https://openaccess.wgtn.ac.nz/articles/thesis/New_methods_for_the_discovery_of_natural_products_from_understudied_and_uncultivated_bacterial_phyla/24187935?file=42439512 (Accessed: 6 June 2025).
Nowak, V.V., Hou, P. and Owen, J.G. (2024) ‘Microbial communities associated with marine sponges from diverse geographic locations harbor biosynthetic novelty’, Applied and Environmental Microbiology, 90(12), e00726-24. Available at: https://doi.org/10.1128/aem.00726-24.
Nunes Ramos, J., Veloso da Costa, L., Viana Vieira, V. and Lima Brandao, M.L. (2025) ‘Challenges in the identification of environmental bacterial isolates from the pharmaceutical industry facility by 16S rRNA gene sequences’, Preprints, [Preprint]. Available at: https://doi.org/10.20944/preprints202503.2316.v1.
Pawlowski, J., Apothéloz-Perret-Gentil, L. and Altermatt, F. (2020) ‘Environmental DNA: What’s behind the term? Clarifying the terminology and recommendations for its future use in biomonitoring’, Molecular Ecology, 29(17), pp. 4258–4263. Available at: https://doi.org/10.1111/mec.15643.
Pearcy, N., Hu, Y., Baker, M., Maciel-Guerra, A., Xue, N., Wang, W., Kaler, J., Peng, Z., Li, F. and Dottorini, T., 2021. Genome-scale metabolic models and machine learning reveal genetic determinants of antibiotic resistance in Escherichia coli and unravel the underlying metabolic adaptation mechanisms. mSystems, 6(2), e00913-20. https://doi.org/10.1128/msystems.00913-20.
Pisupati, B. and Sathyarajan, S., 2022. The need for a Nagoya Protocol ‘Plus’—access and benefit sharing in the context of digital sequence information. In: O.V. Oommen, K.P. Laladhas, P. Nelliyat and B. Pisupati, eds. Biodiversity conservation through access and benefit sharing (ABS). Cham: Springer, pp.349–359. https://doi.org/10.1007/978-3-031-16186-5_18.
Prado-Alonso, L., Pérez-Victoria, I., Malmierca, M.G., Montero, I., Rioja-Blanco, E., Martín, J., Reyes, F., Méndez, C., Salas, J.A. and Olano, C. (2022) ‘Colibrimycins, novel halogenated hybrid polyketide synthase-nonribosomal peptide synthetase (PKS-NRPS) compounds produced by Streptomyces sp. strain CS147’, Applied and Environmental Microbiology, 88(1), e01839-21. Available at: https://doi.org/10.1128/AEM.01839-21.
Qu, G., Liu, Y., Ma, Q., Li, J., Du, G., Liu, L. and Lv, X., 2023. Progress and prospects of natural glycoside sweetener biosynthesis: a review. Journal of Agricultural and Food Chemistry, 71(43), pp.15843–15859. https://doi.org/10.1021/acs.jafc.3c05074.
Rachedi, A. (2023) ‘Teixobactin: an antibiotic from soil bacteria for fighting multiple antibiotic resistance phenomena’, Journal of Concepts in Structural Biology & Bioinformatics, 2(1), pp. 1–4. Available at: https://bioinformatics.univ-saida.dz/jsbb/June_2023/Teixobactin_Soil_Antibiotic_4_Multiple_Antibiotic_Resistance.pdf (Accessed: 6 June 2025).
Rampelotto, P.H., 2024. Extremophiles and extreme environments: a decade of progress and challenges. Life, 14(3), 382. Available at: https://doi.org/10.3390/life14030382 [Accessed 6 Jun. 2025].
Rawat, M., Chauhan, M. and Pandey, A., 2024. Extremophiles and their expanding biotechnological applications. Archives of Microbiology, 206, p.247. Available at: https://doi.org/10.1007/s00203-024-03981-x [Accessed 6 Jun. 2025].
Rebets, Y., Kormanec, J., Lutzhetskyy, A., Bernaerts, K. and Anné, J. (2023) ‘Cloning and expression of metagenomic DNA in Streptomyces lividans and its subsequent fermentation for optimized production’, in Streit, W.R. and Daniel, R. (eds.) Metagenomics. Methods in Molecular Biology, vol. 2555. New York, NY: Humana. Available at: https://doi.org/10.1007/978-1-0716-2795-2_16.
Robinson, S.L., Piel, J. and Sunagawa, S. (2021) ‘A roadmap for metagenomic enzyme discovery’, Natural Product Reports, 38(11), pp. 1994–2023. Available at: https://doi.org/10.1039/D1NP00006C.
Rosenzweig, A.F., Burian, J. and Brady, S.F. (2023) ‘Present and future outlooks on environmental DNA-based methods for antibiotic discovery’, Current Opinion in Microbiology, 75, 102335. Available at: https://doi.org/10.1016/j.mib.2023.102335.
Salamzade, R., Cheong, J.Z.A., Sandstrom, S., Swaney, M.H., Stubbendieck, R.M., Starr, N.L., Currie, C.R., Singh, A.M. and Kalan, L.R., 2023. Evolutionary investigations of the biosynthetic diversity in the skin microbiome using lsaBGC. Microbial Genomics, 9(4), p.000988. https://doi.org/10.1099/mgen.0.000988.
Seshadri, R., Roux, S., Huber, K.J., Wu, D., Yu, S., Udwary, D. et al. (2022) ‘Expanding the genomic encyclopedia of Actinobacteria with 824 isolate reference genomes’, Cell Genomics, 2(12), Article 100213. Available at: https://doi.org/10.1016/j.xgen.2022.100213.
Setubal, J.C. (2021) ‘Metagenome-assembled genomes: concepts, analogies, and challenges’, Biophysical Reviews, 13(6), pp.905–909. Available at: https://doi.org/10.1007/s12551-021-00865-y.
Seyed, M.A. and Ayesha, S., 2021. Marine-derived pipeline anticancer natural products: a review of their pharmacotherapeutic potential and molecular mechanisms. Future Journal of Pharmaceutical Sciences, 7, p.203. https://doi.org/10.1186/s43094-021-00350-z.
Shao, Z., Zhao, H. and Zhao, H., 2013. DNA assembler, an in vivo genetic method for rapid construction of biochemical pathways. Nucleic Acids Research, 37(2), e16. https://doi.org/10.1093/nar/gkn991.
Shetty, R.P., Endy, D. and Knight, T.F., 2008. Engineering BioBrick vectors from BioBrick parts. Journal of Biological Engineering, 2(5), pp.1–12. https://doi.org/10.1186/1754-1611-2-5.
Simon, S.A., Schmidt, K., Griesdorn, L., Soares, A.R., Bornemann, T.L.V. and Probst, A.J., 2023. Dancing the Nanopore limbo – Nanopore metagenomics from small DNA quantities for bacterial genome reconstruction. BMC Genomics, 24, p.727. https://doi.org/10.1186/s12864-023-09853-w.
Skellam, E., Rajendran, S. and Li, L. (2024) ‘Combinatorial biosynthesis for the engineering of novel fungal natural products’, Communications Chemistry, 7, Article 89. Available at: https://doi.org/10.1038/s42004-024-01172-9.
Skinnider, M.A., Merwin, N.J., Johnston, C.W. and Magarvey, N.A., 2017. PRISM 3: expanded prediction of natural product chemical structures from microbial genomes. Nucleic Acids Research, 45(W1), pp.W49–W54. https://doi.org/10.1093/nar/gkx320.
Sun, R., Guo, F., Zhang, Y., Shao, H., Yang, X., Wang, C. and Yang, C. (2025) ‘Biological activity of secondary metabolites of actinomycetes and their potential sources as antineoplastic drugs: a review’, Frontiers in Microbiology, 10 May. Available at: https://doi.org/10.3389/fmicb.2025.1550516.
Theroux, S., Sepulveda, A., Abbott, C.L., Gold, Z., Watts, A.W., Hunter, M.E., Klymus, K.E., Hirsch, S.L., Craine, J.M., Jones, D.N., Brown, R.J., Steele, J.A., Takahashi, M., Noble, R.T. and Darling, J.A., 2024. What is eDNA method standardisation and why do we need it? Metabarcoding and Metagenomics, 9, e132076. https://doi.org/10.3897/mbmg.9.132076.
Tippelt, A. and Nett, M. (2021) ‘Saccharomyces cerevisiae as host for the recombinant production of polyketides and nonribosomal peptides’, Microbial Cell Factories, 20, Article 161. Available at: https://doi.org/10.1186/s12934-021-01650-y.
Torkamanian-Afshar, M., Nematzadeh, S., Tabarzad, M., Najafi, A., Lanjanian, H. and Masoudi-Nejad, A., 2021. In silico design of novel aptamers utilizing a hybrid method of machine learning and genetic algorithm. Molecular Diversity, 25, pp.1395–1407. https://doi.org/10.1007/s11030-021-10192-9.
Van Goethem, M.W., Osborn, A.R., Bowen, B.P., Andeer, P.F., Swenson, T.L., Clum, A., Riley, R., He, G., Koriabine, M., Sandor, L., Yan, M., Daum, C.G., Yoshinaga, Y., Makhalanyane, T.P., Garcia-Pichel, F., Visel, A., Pennacchio, L.A., O’Malley, R.C. and Northen, T.R. (2021) ‘Long-read metagenomics of soil communities reveals phylum-specific secondary metabolite dynamics’, Communications Biology, 4, Article 1302. Available at: https://doi.org/10.1038/s42003-021-02809-4.
Wang, X., Lin, P., Shen, Q., Feng, X., Xu, S., Zhang, Q., Liu, Y., Ren, C., Yong, D., Duan, Q., Huo, L., Zhang, Y., Li, G., Fu, J. and Li, R. (2025) ‘A highly efficient heterologous expression platform to facilitate the production of microbial natural products in Streptomyces’, Microbial Cell Factories, 24, Article 105. Available at: https://doi.org/10.1186/s12934-025-02722-7.
Waschulin, V., Borsetto, C., James, R., Newsham, K.K., Donadio, S., Corre, C. and Wellington, E. (2022) ‘Biosynthetic potential of uncultured Antarctic soil bacteria revealed through long-read metagenomic sequencing’, The ISME Journal, 16(1), pp. 101–111. Available at: https://doi.org/10.1038/s41396-021-01052-3.
Wu, J., Yang, X., Zhao, L., Li, Z., Zhao, G. and Zhang, L., 2025. Systematic characterization of horizontally transferred biosynthetic gene clusters in the human gut microbiota using HTBGC-Finder. iMeta, 2(1), p.e62. https://doi.org/10.1002/imo2.62
Yadav, A. and Subramanian, S. (2024) ‘HiFiBGC: an ensemble approach for improved biosynthetic gene cluster detection in PacBio HiFi-read metagenomes’, BMC Genomics, 25, Article 1096. Available at: https://doi.org/10.1186/s12864-024-10950-7.
Yaraguppi, D.A., Deshpande, S.H., Bagewadi, Z.K., Kumar, S. and Muddapur, U.M., 2021. Genome analysis of Bacillus aryabhattai to identify biosynthetic gene clusters and in silico methods to elucidate its antimicrobial nature. International Journal of Peptide Research and Therapeutics, 27, pp.1331–1342. https://doi.org/10.1007/s10989-021-10171-6.
Yuan, L., Wu, S., Tian, K., Wang, S., Wu, H. and Qiao, J. (2024) ‘Nisin-relevant antimicrobial peptides: synthesis strategies and applications’, Food & Function. Available at: https://doi.org/10.1039/D3FO05619H.
Zdouc, M.M., Blin, K., Louwen, N.L.L., Navarro, J., Loureiro, C., Bader, C.D., Bailey, C.B., Barra, L., Booth, T.J., Bozhüyük, K.A.J., Cediel-Becerra, J.D.D., Charlop-Powers, Z., Chevrette, M.G., Chooi, Y.H., D’Agostino, P.M., de Rond, T., Del Pup, E., Duncan, K.R., Gu, W., Hanif, N., Helfrich, E.J.N., Jenner, M., Katsuyama, Y., Korenskaia, A., Krug, D., Libis, V., Lund, G.A., Mantri, S., Morgan, K.D., Owen, C., Phan, C.-S., Philmus, B., Reitz, Z.L., Robinson, S.L., Singh, K.S., Teufel, R., Tong, Y., Tugizimana, F., Ulanova, D., Winter, J.M., Aguilar, C., Akiyama, D.Y.A., Al-Salihi, S.A.A., Alanjary, M., Alberti, F., Aleti, G., Alharthi, S.A., Arias Rojo, M.Y., Arishi, A.A., Augustijn, H.E., Avalon, N.E., Avelar-Rivas, J.A., Axt, K.K., Barbieri, H.B., Barbosa, J.C.J., Barboza Segato, L.G., Barrett, S.E., Baunach, M., Beemelmanns, C., Beqaj, D., Berger, T., Bernaldo-Agüero, J., Bettenbühl, S.M., Bielinski, V.A., Biermann, F., Borges, R.M., Borriss, R., Breitenbach, M., Bretscher, K.M., Brigham, M.W., Buedenbender, L., Cano-Prieto, C., Capela, J., Carrion, V.J., Carter, R.S., Castelo-Branco, R., Castro-Falcón, G., Chagas, F.O., Charria-Girón, E., Chaudhri, A.A., Chaudhry, V., Choi, H., Choi, Y., Choupannejad, R., Chromy, J., Chue Donahey, M.S., Collemare, J., Connolly, J.A., Creamer, K.E., Crüsemann, M., Cruz, A.A., Cumsille, A., Dallery, J.-F., Damas-Ramos, L.C., Damiani, T., de Kruijff, M., Delgado Martín, B., Della Sala, G., Dillen, J., Doering, D.T., Dommaraju, S.R., Durusu, S., Egbert, S., Ellerhorst, M., Faussurier, B., Fetter, A., Feuermann, M., Fewer, D.P., Foldi, J., Frediansyah, A., Garza, E.A., Gavriilidou, A., Gentile, A., Gerke, J., Gerstmans, H., Gomez-Escribano, J.P., González-Salazar, L.A., Grayson, N.E., Greco, C., Gris Gomez, J.E., Guerra, S., Guerrero Flores, S., Gurevich, A., Gutiérrez-García, K., Hart, L., Haslinger, K., He, B., Hebra, T., Hemmann, J.L., Hindra, H., Höing, L., Holland, D.C., Holme, J.E., Horch, T., Hrab, P., Hu, J., Huynh, T.-H., Hwang, J.-Y., Iacovelli, R., Iftime, D., Iorio, M., Jayachandran, S., Jeong, E., Jing, J., Jung, J.J., Kakumu, Y., Kalkreuter, E., Kang, K.B., Kang, S., Kim, W., Kim, G.J., Kim, H., Kim, H.U., Klapper, M., Koetsier, R.A., Kollten, C., Kovács, Á.T., Kriukova, Y., Kubach, N., Kunjapur, A.M., Kushnareva, A.K., Kust, A., Lamber, J., Larralde, M., Larsen, N.J., Launay, A.P., Le, N.-T.-H., Lebeer, S., Lee, B.T., Lee, K., Lev, K.L., Li, S.-M., Li, Y.-X., Licona-Cassani, C., Lien, A., Liu, J., Lopez, J.A.V., Machushynets, N.V., Macias, M.I., Mahmud, T., Maleckis, M., Martinez-Martinez, A.M., Mast, Y., Maximo, M.F., McBride, C.M., McLellan, R.M., Mehta Bhatt, K., Melkonian, C., Merrild, A., Metsä-Ketelä, M., Mitchell, D.A., Müller, A.V., Nguyen, G.-S., Nguyen, H.T., Niedermeyer, T.H.J., O’Hare, J.H., Ossowicki, A., Ostash, B.O., Otani, H., Padva, L., Paliyal, S., Pan, X., Panghal, M., Parade, D.S., Park, J., Parra, J., Pedraza Rubio, M., Pham, H.T., Pidot, S.J., Piel, J., Pourmohsenin, B., Rakhmanov, M., Ramesh, S., Rasmussen, M.H., Rego, A., Reher, R., Rice, A.J., Rigolet, A., Romero-Otero, A., Rosas-Becerra, L.R., Rosiles, P.Y., Rutz, A., Ryu, B., Sahadeo, L.-A., Saldanha, M., Salvi, L., Sánchez-Carvajal, E., Santos-Medellin, C., Sbaraini, N., Schoellhorn, S.M., Schumm, C., Sehnal, L., Selem, N., Shah, A.D., Shishido, T.K., Sieber, S., Silviani, V., Singh, G., Singh, H., Sokolova, N., Sonnenschein, E.C., Sosio, M., Sowa, S.T., Steffen, K., Stegmann, E., Streiff, A.B., Strüder, A., Surup, F., Svenningsen, T., Sweeney, D., Szenei, J., Tagirdzhanov, A., Tan, B., Tarnowski, M.J., Terlouw, B.R., Rey, T., Thome, N.U., Torres Ortega, L.R., Tørring, T., Trindade, M., Truman, A.W., Tvilum, M., Udwary, D.W., Ulbricht, C., Vader, L., van Wezel, G.P., Walmsley, M., Warnasinghe, R., Weddeling, H.G., Weir, A.N.M., Williams, K., Williams, S.E., Witte, T.E., Wood Rocca, S.M., Yamada, K., Yang, D., Yang, D., Yu, J., Zhou, Z., Ziemert, N., Zimmer, L., Zimmermann, A., Zimmermann, C., van der Hooft, J.J.J., Linington, R.G., Weber, T. and Medema, M.H., 2025. MIBiG 4.0: advancing biosynthetic gene cluster curation through global collaboration. Nucleic Acids Research, 53(D1), pp.D678–D690. https://doi.org/10.1093/nar/gkae1115
Zhang, J., Zhang, D., Xu, Y., Zhang, J., Liu, R., Gao, Y., Shi, Y., Cai, P., Zhong, Z., He, B., Li, X., Zhou, H., Chen, M. and Li, Y.-X. (2025) ‘Large-scale biosynthetic analysis of human microbiomes reveals diverse protective ribosomal peptides’, Nature Communications, 16, Article 3054. Available at: https://doi.org/10.1038/s41467-025-58280-w.
Zhang, J.J., Moore, B.S. and Tang, X. (2018) ‘Engineering Salinispora tropica for heterologous expression of natural product biosynthetic gene clusters’, Applied Microbiology and Biotechnology, 102(19), pp. 8437–8446. Available at: https://doi.org/10.1007/s00253-018-9283-z.
Zhang, W., Fan, X., Shi, H., Li, J., Zhang, M., Zhao, J. and Su, X. (2023) ‘Comprehensive assessment of 16S rRNA gene amplicon sequencing for microbiome profiling across multiple habitats’, Microbiology Spectrum, 11(4), e00563-23. Available at: https://doi.org/10.1128/spectrum.00563-23.
Zhou, Y., Liu, M. and Yang, J. (2022) ‘Recovering metagenome-assembled genomes from shotgun metagenomic sequencing data: Methods, applications, challenges, and opportunities’, Microbiological Research, 260, 127023. Available at: https://doi.org/10.1016/j.micres.2022.127023.
Ziemert, N., Alanjary, M. and Weber, T., 2016. The evolution of genome mining in microbes – a review. Natural Product Reports, 33(8), pp.988–1005. https://doi.org/10.1039/c6np00025h.
Explore Recent Blogs
-
How to Write a Detailed Report: From Planning to Polishingby arora.vijay27jan on January 29, 2026
A detailed report represents critical research and professional competency. Reports provide readers with a comprehensive understanding of the information presented in a coherent format. In addition to reporting the details of a specific situation or… The post How to Write a Detailed Report: From Planning to Polishing first appeared on Digi Assignment Help.
-
How to Write an Assignment on the First Pageby arora.vijay27jan on January 13, 2026
Mastering the skill of writing assignments is one of the most essential academic skills for every student. While most focus on what is contained in the body of the assignment, students frequently overlook the significance… The post How to Write an Assignment on the First Page first appeared on Digi Assignment Help.
-
Most Controversial Debate Topics To Win Any Argumentby arora.vijay27jan on January 12, 2026
Debates are not simply casual conversations about what you think or feel on a specific subject, but rather well-organised and structured forms of discourse in which opposing sides analyse and defend their respective opinions, using… The post Most Controversial Debate Topics To Win Any Argument first appeared on Digi Assignment Help.
-
Significance Of Report Writingby arora.vijay27jan on January 9, 2026
The report is an important part of academic and professional life because it allows individuals to document information systematically, clearly, and indiscriminately so readers can make informed decisions about how to utilise that information for… The post Significance Of Report Writing first appeared on Digi Assignment Help.
-
How to Write a Hypothesis? Step-by-Step Guide with Examplesby Amelia on January 2, 2026
Many students must have experienced the “appear or disappear” situation when formulating a hypothesis for a new research venture. You are certainly not alone if you embark on a new research project and are unsure… The post How to Write a Hypothesis? Step-by-Step Guide with Examples first appeared on Digi Assignment Help.
-
How to Choose the Right Nursing Topic for Your Final-Year Projectby Amelia on July 8, 2025
Nursing is a competitive course offering a promising career for students. It is rigorous and demands up to date knowledge of the subject, good assignment writing, and field practice. Hence scoring good marks in nursing… The post How to Choose the Right Nursing Topic for Your Final-Year Project first appeared on Digi Assignment Help.